



Disaster Recovery Testing: Everything to Know
Disaster recovery (DR) testing is integral to ensuring an organization can effectively respond to any kind of disaster to safeguard data, maintain operations and limit vulnerability.

Disasters come in many forms—from natural disasters and equipment failures to cyberattacks and simple human error. Regardless of the kind of disaster, the results can be devastating if the right processes are not in place. While many organizations focus on the disaster recovery plan, the disaster recovery test deserves equal attention.
What is Disaster Recovery Testing?
DR testing is a proactive process that examines and validates an organization’s DR plan to ensure data, applications and overall operations can be restored within an appropriate timeframe after a service disruption. The process is intended to evaluate the efficacy of the steps and processes outlined in the plan to give an organization a realistic look at how well its DR plan will perform before a disaster strikes. This allows the organization to resolve any weaknesses or inconsistencies in the DR plan that might hinder its recovery from a disruption.
Why is Disaster Recovery Testing Important?
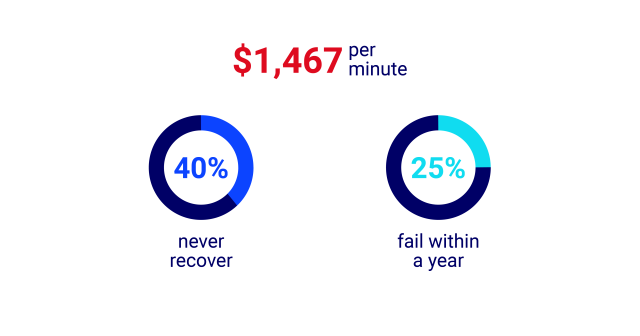
Unplanned downtime is expensive and can have extreme consequences for an organization—from lost revenue, data and productivity to compliance breaches and a damaged brand image. With the cost of downtime estimated at $1,467 per minute, these costs can add up quickly. In fact, according to FEMA, 40% of businesses never recover from a disaster, and an additional 25% fail within a year.
Disaster recovery testing verifies the effectiveness of the DR plan prior to a disaster, offering opportunities to make necessary adjustments. This preparation is key to effectively responding to—and potentially surviving—a disaster. A recent 451 Research study found that more than 30% of respondents experienced an outage that resulted in lost data or affected worker productivity in the last two years, while nearly a third of organizations lost more than $1 million as a result of their most recent outage.
While having a DR plan is a vital first step in avoiding these costly outages, performing frequent tests of that plan is equally important to help identify issues and gaps within the plan or staff members’ inability to carry out the necessary processes.
Despite the criticality of testing to ensure a seamless recovery, only 37% of organizations test disaster recovery once a year and only 21% of respondents test more than twice a year, according to the 451 Research Business Impact Brief. This leaves tremendous room for something to go wrong, especially given that IT environments are rarely static. To ensure the validity and smooth execution of the recovery, 451 Research recommends increasing DR testing frequency to “keep up with dynamic environments.”
What is the Goal of Disaster Recovery Testing?
DR testing is designed to ensure the DR plan works as expected and to provide insight into areas that need attention.
Identify and Rectify Issues
The main purpose of a DR test is to provide an opportunity to identify and correct ineffective or broken processes prior to a crisis. Post-test analyses are utilized to discuss the successes and shortcomings of the plan and incorporate those lessons into the DR plan to promote a seamless rollout amidst a real disaster.
Meet RTO/RPO Objectives
DR tests also ensure recovery time objectives (RTO) and recovery point objectives (RPO), which pinpoint how quickly service must be restored and the necessary frequency of backups to prevent data loss, respectively. While these metrics vary depending on the individual business, meeting them is essential to limit exposure and optimize recovery efforts.
Define Responsibilities
The DR test also ensures that process stakeholders understand their responsibilities and can execute them effectively during a disaster. When this is not the case, it allows opportunities for additional training.
Benefits of Disaster Recovery Testing for Your Business
By enabling an effective and rapid restoration process, organizations protect themselves against business-impacting disruptions.
Minimizing Downtime
Organizations that are not prepared when disaster strikes may face excessive downtime as they struggle to recover their systems and pinpoint where their DR plans went wrong.
Control Costs
Downtime results in lost dollars, and the longer systems are down the more costly it becomes. DR testing helps limit downtime that can impact the bottom line through lost revenue, hindered productivity, noncompliance penalties and legal fees, customer churn and more.
Remain Compliant
Meeting regulatory compliance expectations is business critical, especially in industries like healthcare and finance that have stringent compliance obligations, such as HIPAA and PCI DSS that require a DR plan. DR testing helps ensure operational resilience, so organizations remain compliant.
Maintain Your Reputation
Downtime can impact an organization’s brand. When customers cannot access the data or services they need, the organization’s reputation can suffer. Frustrated customers are more likely to move on from a brand to a competitor, impacting the bottom line.
Types of Disaster Recovery Testing
DR testing can be time consuming and resource intense. This can cause some organizations to delay this critical process. However, there are three types of DR tests, each with a different effort level, to allow organizations to conduct frequent testing:
A Plan Review
With a plan review, process stakeholders carefully examine each step of the DR plan to detect and amend any missing elements or issues to ensure all environmental changes have been documented.
A Tabletop Exercise
A tabletop exercise takes the plan review a step forward, requiring the DR team to physically walk through each step of the DR plan to assess the effectiveness of the recovery process and stakeholders’ understanding of their responsibilities.
A Simulation Test
Simulation testing is designed to provide a real-world look at the DR plan without impacting normal business operations. The approach involves mimicking a specific disaster event, such as a natural disaster or equipment failure, to see if the established recovery processes are effective.
Disaster Recovery Testing Techniques
DR testing can utilize multiple techniques, each of which replicates critical applications and data at a secondary site to support system availability and security while the primary site is down. DR testing techniques include:
Synchronous Replication
With synchronous replication, data is replicated to the primary and secondary locations simultaneously. Because this approach writes data to both locations simultaneously, the locations must be near each other to support performance. This technique is generally used to support applications that require instant failover capabilities.
Asynchronous Replication
Asynchronous replication copies data to the primary site first and then to the secondary site. This approach does not have any geographic limitations and is, therefore, frequently used for applications with distant environments. This method is effective when a local event, such as any kind of natural disaster impacts an area.
Mixed Replication Technique
As the name suggests, this technique integrates both the synchronous and asynchronous approaches. With mixed replication, systems are replicated via the synchronous technique at a local site with another copy further away.
Disaster Recovery Testing Best Practices
DR testing requires an investment of both time and resources from an organization to keep pace with system and application changes. Without appropriate testing, there is a strong probability the DR plan could fail. To best support a successful recovery, organizations should embrace DR testing best practices.
Commit to Frequent DR Testing
IT environments are dynamic. Performing regular DR testing can help keep pace with changes by identifying and rectifying issues in the DR plan, so recovery efforts are effective in a real crisis. Organizations need to determine the appropriate testing cadence for their businesses and commit to this schedule to ensure the integrity of the DR plan.
Engage a DR Test After Changes
Major infrastructure changes can alter recovery procedures and require plan modifications. Conducting a test after a reformation assures the new environment is represented in the plan.
Understand the Business Impact
Organizations can execute live testing or parallel testing to evaluate their DR plans. While live testing is the most thorough, it has a heightened risk factor as it purposefully brings down systems before attempting to recover them. This can instigate downtime if recovery efforts fail. Parallel testing does not disrupt business operations. Instead, it utilizes a recovery system that mirrors the production environment, allowing the DR team to test the recovery systems while the production environment operates in parallel. While this is not a full test, it provides insight into backup and restoration capabilities and helps identify other concerns. Organizations must understand the potential impacts of these tests and choose the process that best meets their needs to avoid unnecessary disruptions.
Test Various Disaster Scenarios
Organizations should be prepared to test for as many disaster scenarios as necessary to address potential risks. For example, natural disasters may require an evacuation as part of the response protocols. Aging equipment and network instability can also impact availability. According to 451 Research, 25% of recent outages were caused by hardware failures and 34% were caused by network failures. DR testing can help identify end-of-life equipment that could struggle to initialize after an outage. To head off issues, organizations should perform a test with a specific disaster in mind.
Evaluate and Document the DR Process
Every DR test should conclude with an analysis of the results of the recovery process to fix problems and improve the plan. The results of the test—including what did not work and how it was corrected—should be clearly documented.
The Rise of Disaster Recovery as a Service
DR testing can be complex and time-consuming, but organizations need to make the commitment to ensure continued operations in the face of any kind of disaster. This is particularly crucial as increasingly sophisticated cyber threats threaten data and the cost of downtime continues to climb.

Organizations that need support with their disaster recovery strategy can leverage a DR partner to help assess, design and implement a strategy that addresses their specific requirements. Cloud-based DR, or disaster recovery as a service (DRaaS), is growing in popularity, according to 451 Research’s Business Impact Brief, Enhancing Application Reliability with Cloud Backup and Disaster-Recovery-as-a-Service. The brief notes that more than 70% of organizations prefer a DR strategy with a cloud-based element.
Disaster recovery as a service (DRaaS) reduces the complexity of the recovery process and offers flexibility that supports organizations’ needs around scalability, recovery speed, cost efficiency and geo-diversity to expand replication capabilities and ensure performance without building out a new environment. It also maintains regular testing cycles to reinforce recovery, while allowing internal teams to focus on other business-enabling initiatives.
Flexential DRaaS offers fully managed services delivered by DR service experts to ensure a secure resiliency strategy that mitigates risk and helps organizations meet required RTO/RPO and compliance requirements. Flexential Professional Services (FPS) can support an organization as it plans, implements and continually tests its DR solution to further improve resiliency.
Conclusion
Organizations have too much at stake to not take their disaster recovery efforts seriously. Successful recovery hinges on the efficacy of each step within the DR plan—and the best way to ensure this is with regular DR testing. Organizations that need support with these efforts can leverage a DRaaS solution to minimize complexity and achieve the security, expertise and performance of a professionally managed and regularly tested recovery strategy. Regardless of the route an organization takes to deliver its disaster recovery, testing the DR plan should not be overlooked as it is the link to protecting data and maintaining uptime.
Download the 451 Research Business Impact Brief for more insight into the state of disaster recovery, and learn how Flexential disaster recovery solutions can help move your recovery efforts forward.
